一言。
以下は、2006年夏頃に認めたものです。
この度当サイトにアップすることといたしました。
一言。
以下は、2006年夏頃に認めたものです。
この度当サイトにアップすることといたしました。
![]()
統計ソフト「R(アール)」を使ってみた体験記です。
![]()
「R」 統計のフリーソフトに、「R」というものがあります。 実は私、以前から統計学(というより、データマイニング?)に興味を抱いていたのですが、何分にも難しすぎて、なかな か手を出したくとも出せない状態が続いておりました。 まあ、その状況は現在をもってしてもまったく同様ではあるのですが、先日「数検3級」を取得したことで、些か数学アレ ルギーからの脱却をはかることが出来たような気がしています。 (不思議なことに、本の中にΣ記号などが出てきたりしても、うっとうしくなくなった…。) 注)「統計」と「データマイニング」は、ちょっと違います。 「統計」は貴重なデータをもとに「推定」や「検定」を行ったりするものですが、「データマイニング」はどちらかと言うと 「ゴミの山」に近いデータの束から、ルール化を発見することです。 それで。 ちょっとやってみました。 ① 九九の計算 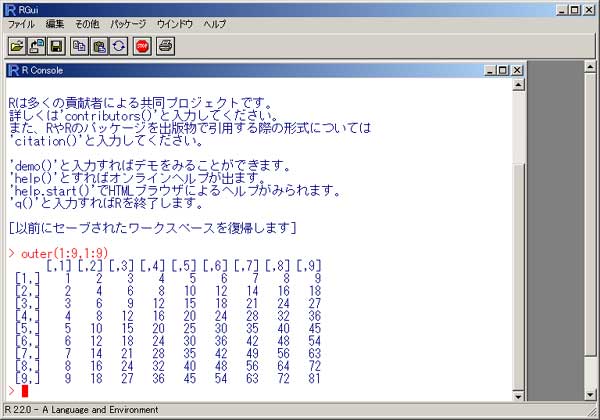 ↑まずはウォーミングアップということで。 九九の計算です。 これは統計と何の関係もございません。(笑) outer(1:9,1:9) でいけました。 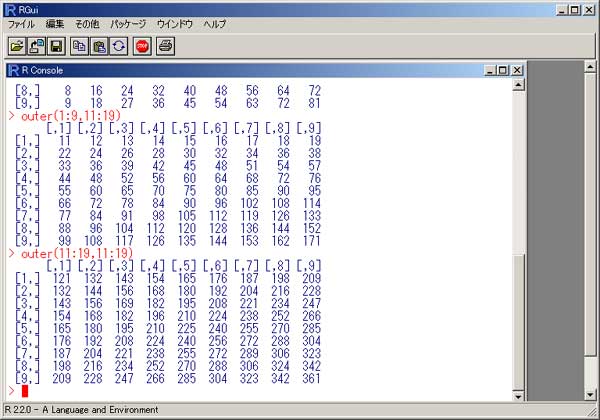 ↑今流行り(?)の、二桁九九です。 二桁九九の暗記本が、最近書店で売られているようですね。 上の画面の二つ、分かりますか? 上が、1-9までの数 × 11-19までの数 の九九 下は、11-19 × 11-19 の九九 となります。 ・・・しかしこんな一発で出るとは、なかなかですなぁ~。 ② 確率 以下は、サイコロのシミュレーションです。 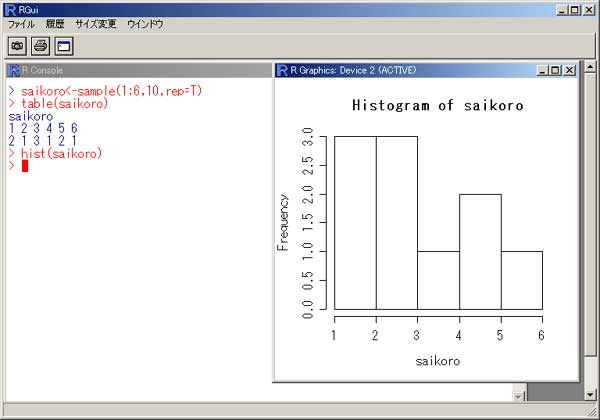 ↑サイコロを10回投げたときの、出た目の回数ですね。 「1」が3回、「2」が3回、・・・・・「6」は1回出ましたよ、ということです。 実際にサイコロを投じなくても、「R」が代わりにやってくれる訳です…。 (「やってくれる」と言っても、仮想シミュレーションですから、瞬時に結果が返ります。) 右は「ヒストグラム」。 要するに、グラフです。 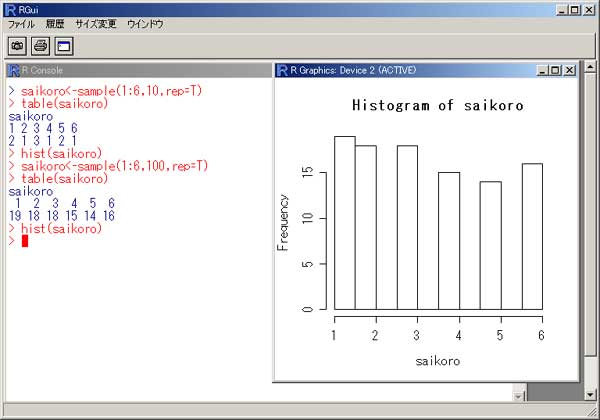 ↑サイコロを100回投げたときのヒストグラム。 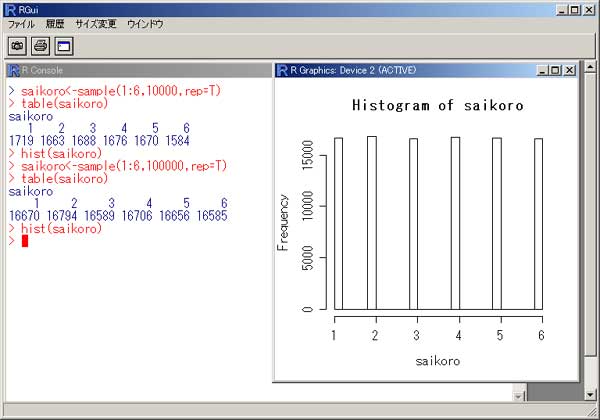 ↑サイコロを10万回投げたときのヒストグラム。 10万回でシミュレーションしますと、ほとんど確率が均衡することが解ります。 (六分の一に、限りなく接近する。) 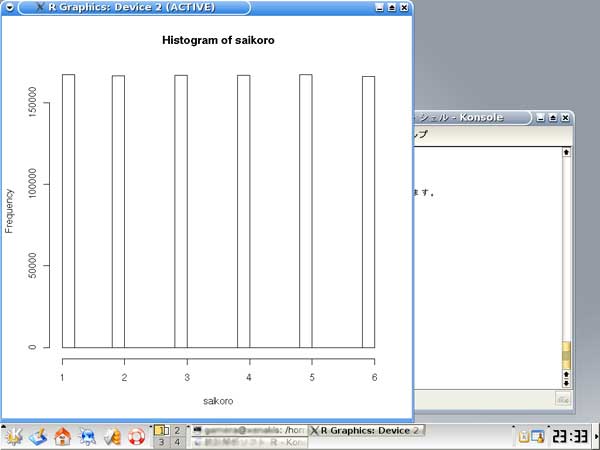 ↑「Debian」にて、100万回シミュレーションを行った結果。 Linux版「R」の方が、ヒストグラムの表示は綺麗かも? ③ 平均値・中央値(メジアン)・再頻値(モード) 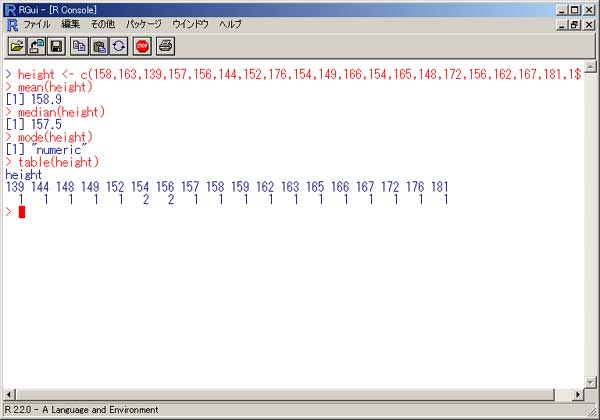 では次。 やっと統計の内容になりました。 でも統計学のイロハの「イ」、です。 一行目にあるのは、サンプルデータ。 サンプルデータを入力しているのです。 このデータは、こちらの本に載っていたもの。 (本サイトの主旨から考えて、転載には問題ないと判断しました。) 「16-20歳の女性20人(をアットランダムに抽出したとき)の身長データ」となっています。 標本抽出ですから、そもそも転載には何の問題もなしですね。 統計学には大きく分けて「記述統計学」と「標本統計学」があり、「標本統計学」は抽出した標本データから、全体を 「推定」するんですね…。(テレビの視聴率などが良い例。) 2行目の mean(height) というのが、平均値です。 算術平均(相加平均)です。 幾何平均はどうするのかと言うと…。 今のところ、わかりません。(ひょっとして機能が無い?) 注)幾何平均とは? 算術平均は、データの和÷データの数 です。(要するに、普通の平均) 幾何平均はデータを全部掛け算し、それを「(データの数)乗根」にしたものです。 ガウスが提唱したらしい。 (これだけでは、わからんかな?) なんか…。 「R」には幾何平均の関数が無いみたい。 実は幾何平均、Excelで簡単に出せるんですね。 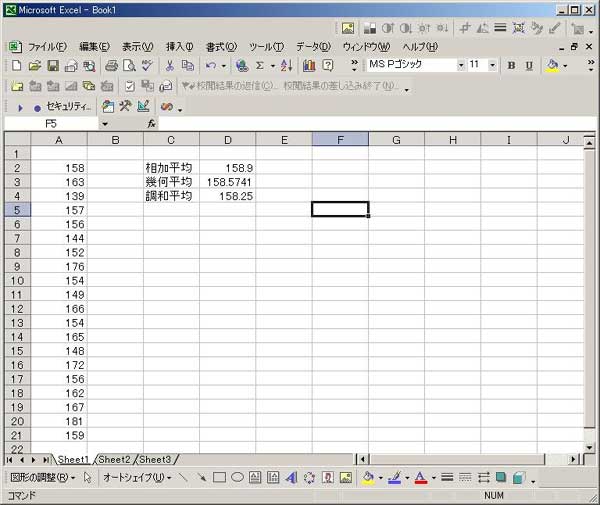 うーん・・・。 さすがExcel! これでは「R」を使用する意味が・・・。(^^;) いやいや。 誰でも使ってるやつ(=Excel)ではやりたくない私、なのでした…。(^^) (ありきたりはイヤなんです。) ちなみに、調和平均とは、逆数の和をデータの数で割り、それをさらに逆数にした値のことです。 (平均速度の算出などに用いるらしい。)  ↑次、行きましょう。 中央値(メジアン)と最頻値(モード)です。 これらの値にどのような意味があるのかについての解説は、省略させていただきます。 (このサイトは「R」について書いているだけで、「統計」について教授するものではありません。) なーんて言って、説明しますけども。 中央値(メジアン)とは、データの昇順(降順でも良い)に並べなおして、ちょうど真ん中にくる値のこと。 最頻値(モード。)とは、データの中で最も数の多い値がどれになるか、ということです。 ファッションで言うところの “モード”とは、似ているようでちと違うかな? “トレンド”といった意味合いは、全くありません。 「この商品は2980円の価格に品揃えが集中している。」のようなとき、2980円が“モード(最頻値)”となります。 「R」には「モード」を算出する関数が無いようです。 代わりに、table関数を用いました。 身長154cmと156cmが、それぞれ2人ずついることが判りますね。 …メジアン、モードがどんなものかまでは解説しましたが、その使い分け・考え方については書いておりません。 (計算式だけ聞かされて、その意味するところについては全然分かっていない人が、統計解析結果を何か宝物の ように珍重なさることがあるらしいのですが、それははっきり言って愚の骨頂です・・・。) 実際、統計学は難しいのです。 統計学を真面目に勉強したいのなら、他人の作ったホームページなど見るよりも、(絶対に!)専門の本を購入され ることをお薦めします。 とりあえず「代表値」については、こちらでもどうぞ。 そうそう。 右横のヒストグラムも是非ご覧下さい。 縦軸の“Frequency(フリークエンシー)”が“度数”(件数)です。 横軸は身長。 ところで、横軸の身長の幅をどう取るかによって、ヒストグラムの形状は随分と変わってしまうもの。 …さっきの中心価格帯(モード)の話でも、書くべきかどうかちょっと考えましたが…。 データをグラフ化したとして、 0~1000円 3個 1001円~2000円 10 2001円~3000円 6個 3001円~4000円 1個 4001円~5000円 0個 という具合に、1000円ごと全部で5つの階級に分けてまとめ、それぞれの個数を掴む場合と 0~750円 751円~1500円 1501円~2250円 2251円~3000円 3001円~3750円 3751円~4500円 4501円~5250円 のような括りにしてやるのと。 一体、どっちがより適切な分析だと、言えるのでしょう?? (区切り方によって、結果帳票が全然違ったものに化けるんです…。) ・・・私は昔から、ここのところがスッゴイ疑問でした。 大概は分析者の人が、価格帯を勝手に(『えいっ、ヤー!』で)区切って、分析されていましたのでね。 ここの「区切り方」については、統計学の分野でも、それほど高度で発展的な理論は無いようです。 中で、実は「スタージェスの公式」というものがあります。 「階級の数」=1+3.3×log n ・・・・・ 「スタージェスの公式」 nはデータの数。 「log n」とは、「10を何乗したらnになるか?」ということです。 この公式に基づいて計算すると、5.29となります。 だから、上の1000円単位で分けてやるやり方が、ベターと思われますね。 (因みにですが、「スタージェスの公式」はデータ数が多いときには使えないらしい…。)  ↑Excelだと簡単にメジアン、モードが算出出来ます。 でも、モードの値がちょっと変ですね。(笑) ・・・「しょせんExcel。」ということでしょうか…。 ④ 分散 標準偏差 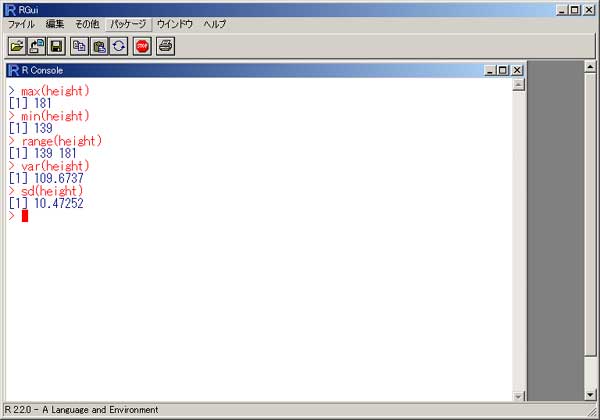 最大値、最小値、レンジ、分散、標準偏差 の順で算出しています。 「分散」や「標準偏差」については、その筋の本をお読みください。 (とりあえずこちらでもどうぞ。) このデータの場合、「平均」が158.9cmで「標準偏差」が10.5cmとなりますから、(この分布を「正規分布」と見做す なら)158.9cm+-(プラスマイナス)10.5cmの範囲内に、全体の68%が存在している、という理屈になります…。 -- -- 発展的内容 -- -- ではなぜ、『158.9cm+-(プラスマイナス)10.5cmの範囲内に、全体の68%が存在している。』ということが言えるのでしょうか? それには、標準正規分布表を用います。 「標準正規分布」とは、「正規分布」を“標準化”したもの。 z=(x-μ)÷σ ・・・・・ 標準化の公式 … 標準正規分布(標準正規変数:z)は、確率変数(x)から平均(μ)を引き、さらにそれを標準偏差(σ)で割ったもの。 この式のように変形してやると、正規分布は平均0、標準偏差1の正規分布(=標準正規分布)に変わってくれるのですね。 早い話が、「単位を合わせてやった方が、考えやすい。」ということです…。 ああ、そう言えば…。 「標準正規分布」の前に、そもそも「正規分布とは何ぞや?」の話を、綺麗に端折っていましたね。 先ほどのリンク先、一番上のグラフをご覧下さい。(自分で図を書くのが面倒なので、リンクでごまかしております。) この図のように、度数の分布がちょうど平均値のところに集中し、平均から左右(プラスマイナス)に遠ざかるに連れ、シンメトリーの ように分布(度数)が緩やかに減っていくような、そんな分布のことを「正規分布」と呼びます。 試験の成績や、身長・体重などが「正規分布に従う」ことが、よく知られています。 (実はその他の分布も、ちょっと計算式を捻ってやることで正規分布に変換することが出来るのです。) でも、そもそも「正規分布」の平均値が0になるなんてことは、まずないですから、 (このことは、例えば英語の平均点を思い浮かべてもらったら良いです。 ああ、そうそう。 上の公式の結果に、10を掛けて50を加えてやれば、 かつての大学受験生たちの間で有名だった「偏差値」となります…。(今の学生は知らないのかな?) 仮にzが0なら(つまり、zが平均値なら)、偏差値は50になりますよね。) (5行上からの続き)これ(正規分布の確率変数x)を「標準化」(x→z)してやることによって、 正規分布を共通の土俵で表すことが出来るようになります。 で、さっきの標準正規分布表の、zが1.0になるところの数値を読んでみてください。 (横軸は、小数点第二位です。) どうですか? 0.8413 と出ていますね。 でも、今求めようとしているのは、標準偏差が1.0のときの確率ですから、(0.8413-0.5)×2 で、0.6826。 よって、68%なのですね。 ・・・・・っていうか、今の説明だけで、なんで84%が68%になったのか? 解った人いたかなぁ~。(^^;) さっきのあのグラフを、もう一度よく見てください。 グラフの下の「正規分布表」が指し示しているのは、グラフで灰色になっている部分の面積(全体を1とおいたときの。)です。 今回は、この灰色部分ではなく、こちらのサイト、上のグラフ図にあるように、両端を外した真ん中の面積を求めなければならないのでした。 だから、(全体で1なので)0.5を引いて2を掛けたという訳です。(^^) ちなみにその下、“95.44%”となっているところ。 ここは解りますか?? “「平均値」プラスマイナス「2σ(標準偏差の2倍)」の枠の中に、全体の95.44%がひしめいている。” という意味ですね。 この数値が大体95%に近いので、「95%信頼区間」などと呼ばれて重宝されているのですが、より正確に計算してみますと、 0.95÷2 = 0.475 ↓ 0.475+0.5 = 0.975 ↓ これを「正規分布表」で確認しますと、1.96 と出ました。 2σの確率である“95.44”で計算しますと、まずはこの値を小数に直して 0.9544 →これを2で割って、 0.4772 →それに0.5を足すと、0.9772 ↓ これをより詳細な「正規分布表」で確認しますと、1.9995 とまあ、少しばかり誤差があるようです…。  似たようなことをExcelでも試してみました。 「Excel」には「偏差平方和」を求める関数もありましたが…、「R」には無いのでしょうか? その他、n(標本の個数)で割る場合とn-1で割る場合と、二通りの関数が存在していました。 これは便利ですねぇ。 この機能も「R」には無いのでしょうか??? (基本的に「標本」の場合は(n-1)を、母集団のときはnを用います。) 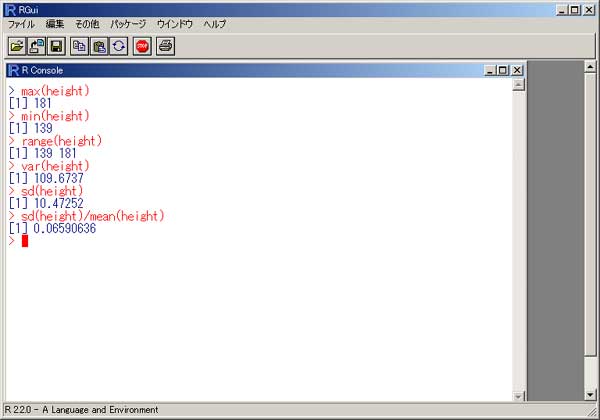 ↑変動係数も求めてみました。 変動係数は、標準偏差÷平均値 で良いです。 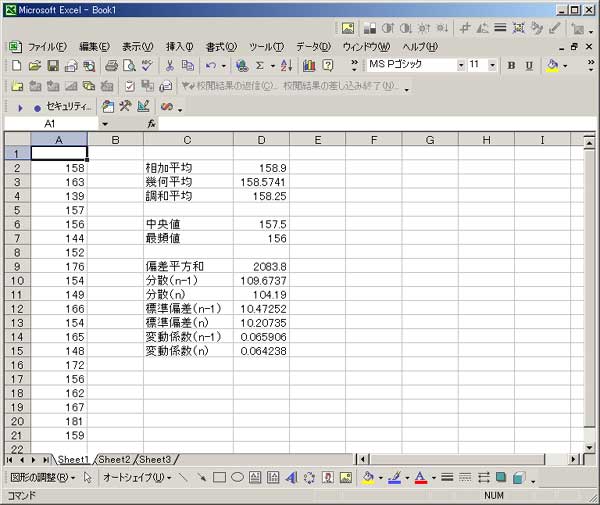 ↑Excelだとこんな感じ。 …「標準偏差」と「変動係数」との違いは、「額」と「比率」の違いに似ています。 企業の売上高なんかでも、「対前年比」で見る考え方と、「額」で見る考え方とありますでしょう? それと同じことです…。 おっと。 そうそう。 Excelでもヒストグラムは作成できます。 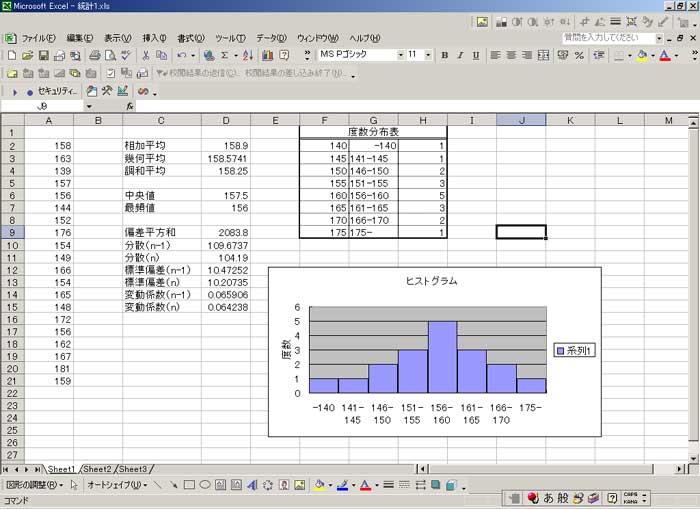 ↑こんな感じ。 「R」の場合、階級は自動で作られましたが、Excelでは自分で階級を指定する必要があります。 ⑤ 確率分布 工事中。 |